新型コロナウィルス感染状況をPythonで出力する

[TOC]
コロナ禍の生活となりもう久しいですね。
一刻も早く収束することを願うばかりです。
今回は、Pythonを使って厚生労働省で公開しているオープンデータを用いて日本の新型コロナウィルスの分析、可視化します。
目的
Python を利用して、厚生労働省が公表している統計情報をもとにグラフ出力し、分析します。
今回は、PCR検査のデータから日ごとの結果を表示させます。
工夫した点やポイント等を解説します。コードは *.py 形式で保存して実行可能です。
※動作を保証するものではありませんのでご了承ください。
オープンデータについて
厚生労働省は、下記のURL でコロナウィルス関連のデータを公開しています。
https://www.mhlw.go.jp/stf/covid-19/open-data.html
今回は上記URLにあるデータを使わせていただいています。
- PCR検査実施人数
- 陽性者数
- PCR検査の実施件数
のデータを使いました。
実行環境
筆者のPC環境は以下となります
- Windows 10 Home (64bit)
- Python 3.9.5
※政府のサイトを直接参照するので、ネットワーク回線は必須です。
Pythonライブラリ
matplotlib と pandas を利用します。
それぞれインストールします。
pip install matplotlib pip install pandas でインストールします。
pip freeze の抜粋
matplotlib==3.3.3
pandas==1.2.0
コード
実際のコードは以下となります。貼り付けて、 <任意の名前>.py で保存し、
コマンドラインから python <任意の名前>.py を実行するとグラフ画面が表示されるはずです。
from datetime import date
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP']
pcr_case_daily = "https://www.mhlw.go.jp/content/pcr_case_daily.csv"
pcr_positive_deily = "https://www.mhlw.go.jp/content/pcr_positive_daily.csv"
pcr_tested_daily = "https://www.mhlw.go.jp/content/pcr_tested_daily.csv"
# URL を入力してデータの加工
def make_dataframe(url, needs_sum=False, diff_column_name=None):
df = pd.read_csv(url)
if needs_sum:
df["合計"] = df.sum(axis=1)
if diff_column_name:
df["差分_{0}".format(diff_column_name)] = df[diff_column_name].diff()
return df
# 移動平均
def rolling(df, key):
df["{0}_移動平均".format(key)] = df[key].rolling(window=5).mean()
return df
# 外部接続
def merge(left,right, key):
df_sum = pd.merge(left, right, on=key, how='outer')
return df_sum
if __name__ == "__main__":
df1 = make_dataframe(pcr_case_daily,True)
df2 = make_dataframe(pcr_positive_deily,False, "PCR 検査陽性者数(単日)")
df3 = make_dataframe(pcr_tested_daily,False)
df_sum = merge(df1, df2, '日付')
df_sum = merge(df_sum, df3, '日付')
df_sum['日付'] = pd.to_datetime(df_sum['日付'])
df_sum.sort_values('日付', inplace=True)
df_sum = df_sum.reset_index()
df_sum = rolling(df_sum,"PCR 検査陽性者数(単日)")
df_sum.plot(x="日付",y="合計")
df_sum["割合"] = df_sum["PCR 検査陽性者数(単日)"] / df_sum["合計"]
df_sum.plot(x="日付",y="割合")
ax1 = df_sum.plot(x="日付",y="PCR 検査陽性者数(単日)")
df_sum.plot(x="日付",y="PCR 検査陽性者数(単日)_移動平均", ax = ax1)
df_sum.plot(x="日付",y="PCR 検査実施件数(単日)")
out_csv_filename = "pcr_{0}.csv".format(date.today())
df_sum.to_csv(out_csv_filename)
plt.show()
解説
このコードのポイントは、以下です。
- matplotlib のグラフ出力で日本語に対応している
- 日付の文字列データを文字列型に加工し、扱いやすくしている
- 移動平均を用いてデータを見やすくしている
- 加工後のデータを csv 形式で保存している
まずは、
from datetime import date
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP']
の部分で、フォントを指定してすることで日本語の部分文字化けさせないようにしています。
これを実行しないと、グラフのタイトルなどが正常に表示されず、いわゆる「豆腐」文字列となると思います。
以下はURL からpandas の Dataframe を出力する自作の関数です。
# URL を入力してデータの加工
def make_dataframe(url, needs_sum=False, diff_column_name=None):
df = pd.read_csv(url)
if needs_sum:
df["合計"] = df.sum(axis=1)
if diff_column_name:
df["差分_{0}".format(diff_column_name)] = df[diff_column_name].diff()
return df
PCR検査のデータは、どうやら各検査所のカテゴリごとに分けて統計値をとっているようなので、
各検査所のその日の検査の和 = その日の全検査数
として合計値の列を作成するようにしています。
pandas.Dataframe.diff 関数を使うと指定した列において、その値からひとつ前の行の値を引き算した値を出力します。
合計値が必要なのは、検査数のデータだけなので、
次に merge 関数で、日付のキーでがっちゃんこします。
df_sum['日付'] = pd.to_datetime(df_sum['日付'])
df_sum.sort_values('日付', inplace=True)
df_sum = df_sum.reset_index()
この部分でいろいろやっていますが日付のキーを python の datetime 型に変換しています。
こうすると、グラフ化するときにいい感じになります。
インデックスを振り直しもしています。
グラフ
こんな感じのグラフが得られると思います。
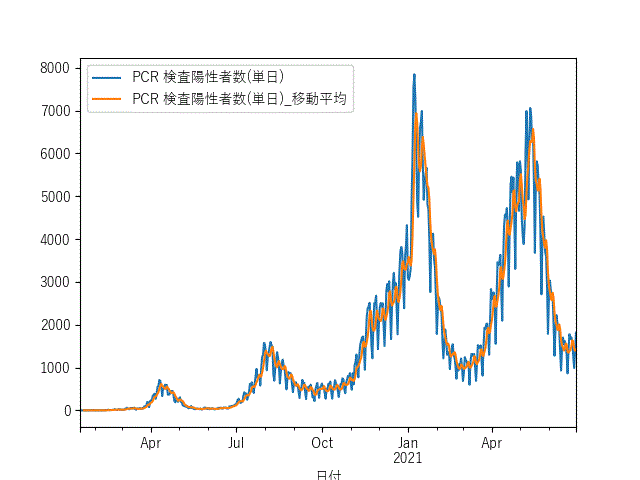
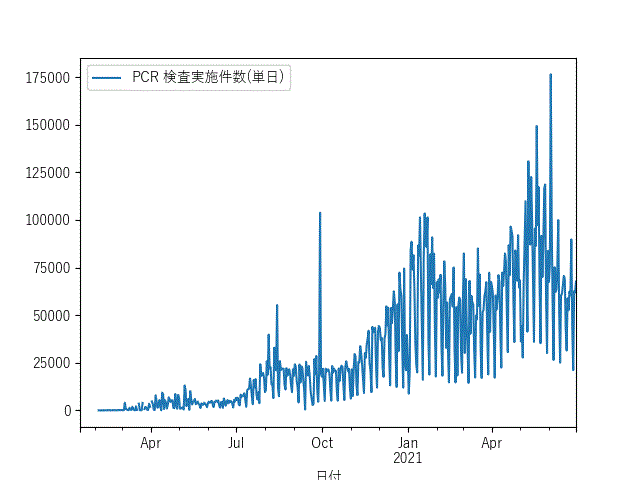
最後に
今回は、単純な日付のデータをプロットしました。
ブログでPython プログラミング技術系の記事を書くのは初めてです。
是非ご指摘があればコメント等ください。
コメント
この記事はコメントがありません。
記事にコメントする